Two-Stream SR-CNNs for Action Recognition in Videos
Publication
Abstract
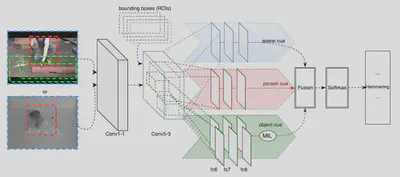
We propose a new deep architecture by incorporating object/human detection results into the framework for action recognition, called two-stream semantic region based CNNs (SR-CNNs). We perform experiments on UCF101 dataset and demonstrate its superior performance to the original two-stream CNNs.
Network Architecture